Analyzing Homographic Phishing Characters
е negates e!
Overview
Recently, I’ve seen a couple of phishing scams hit a few of my friends on Facebook (yes, I still use that thing), and after I asked how they fell for something like this, they replied with “Well, it looked nearly identical to the real Facebook url.”
This made me investigate further into this for a bit. I thought that the general lecture I gave to my friends that “it’s one of those common sense things to check links so you’re not actually going to like fàcèbook or whatever” kept them safe – but when it’s characters that literally look like the exact same, but are two different symbols (such as a and а, becomes a potential concern for phishing attacks. Allow me to elaborate.
Let’s compare the difference between this е and this e:
Googling the former:
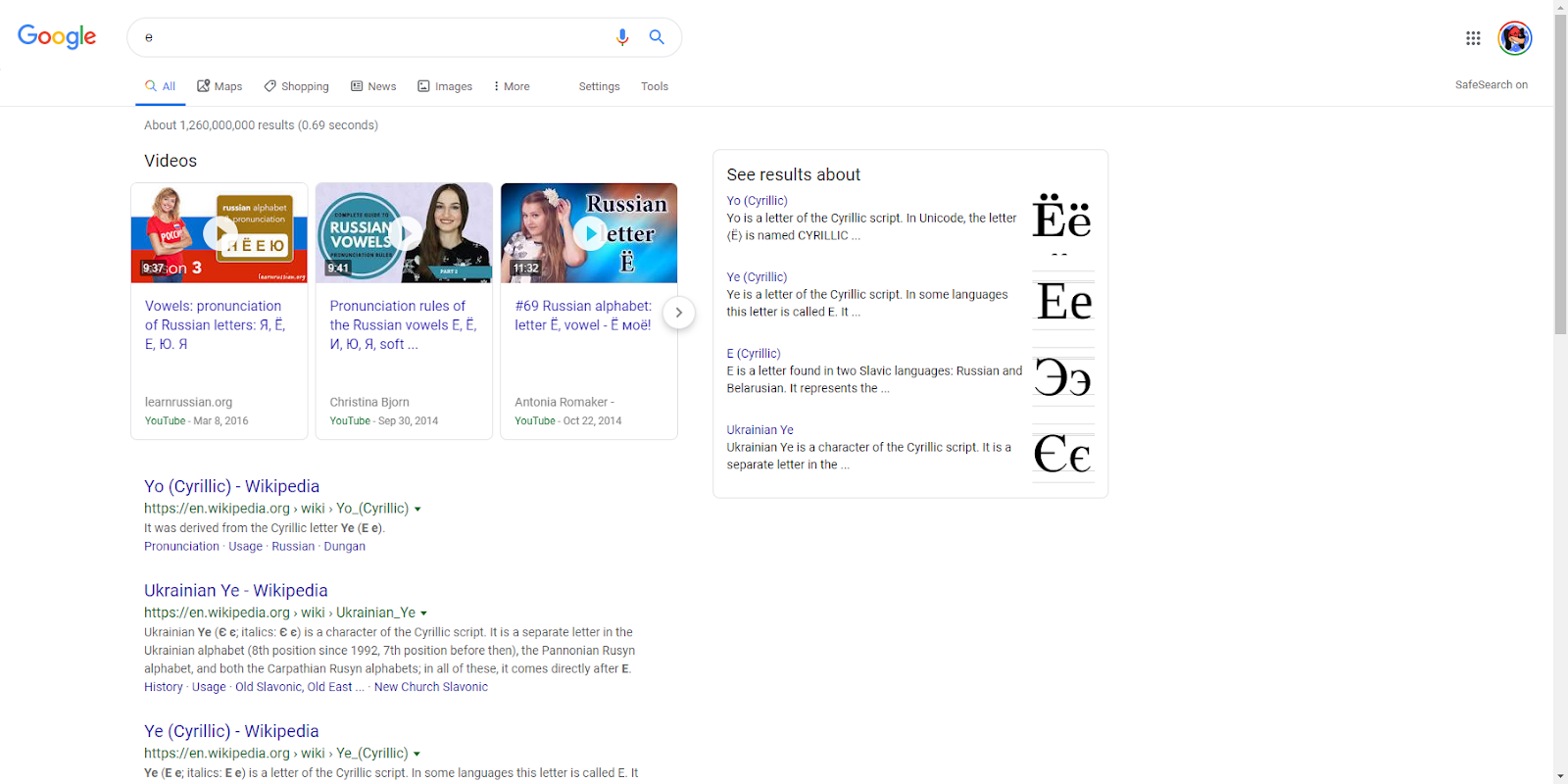
Googling the latter:
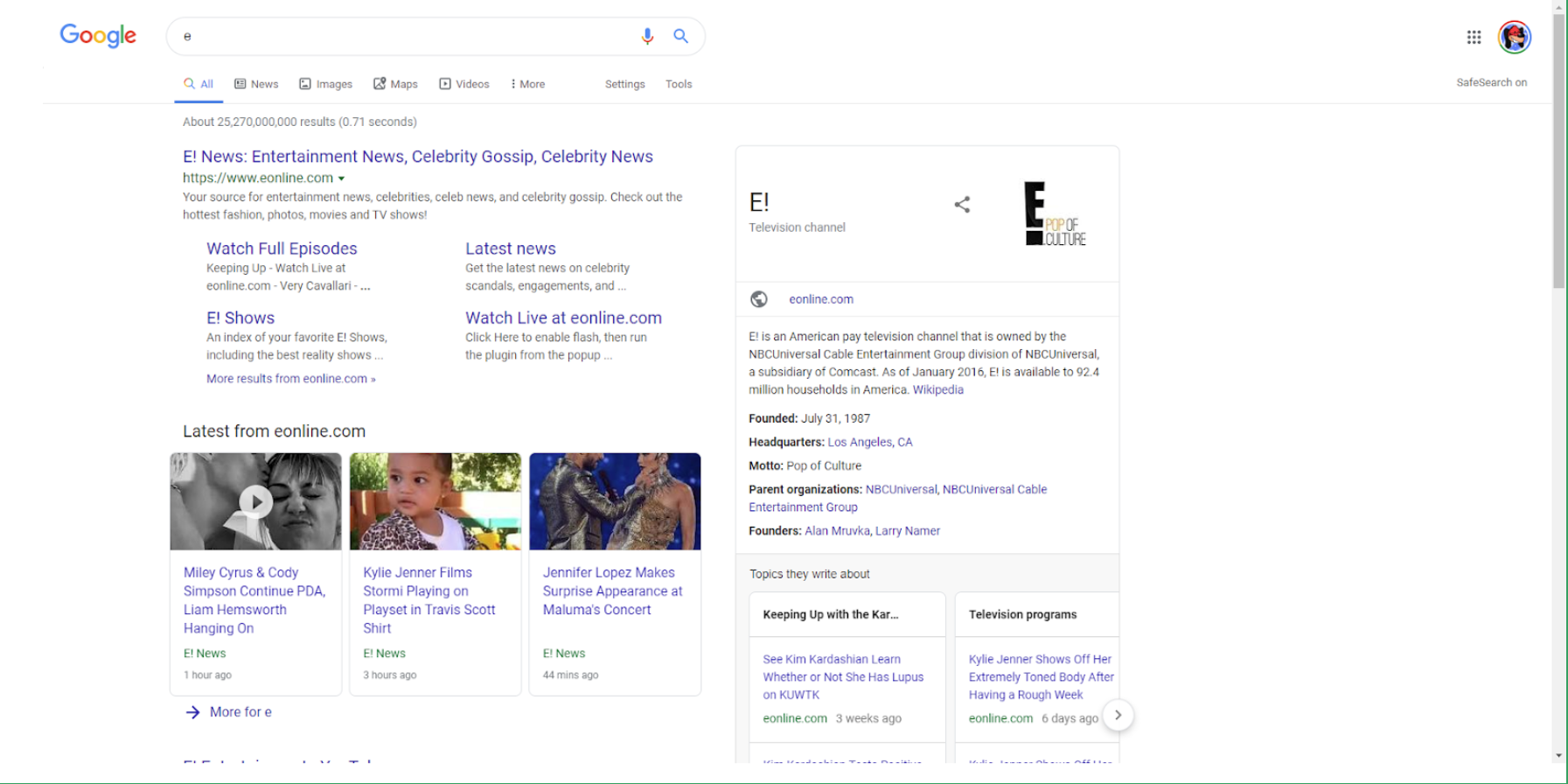
So why does this exist?
I’m not going to get really technical here when it comes to historic alphabet development, but when the Latin alphabet, Cyrillic alphabet[s] and the Greek alphabet were being developed, they ended up deriving similar letters from each other. As an example, both the Latin character “a” and Cyrllic character “а” were derived from the Greek character “α” (alpha), but are localized to two different regions of the world.
Similar things could be said in the Latin alphabet, where the lowercase L “l” and the uppercase i “I” look extremely identical to each other. In addition, combining “rn” together can deceive people to think it’s the character “m” instead. At first glance, the domain “rnicrosoft.com” could look like a legitimate website, or even “steamcornmunlty.com”, but “microsoft” negates “rnicrosoft” and “steamcommunity” negates “steamcornmunlty”.
The similarities between these characters are formally described as “homographs”: when two words look alike, but have two completely different meanings. Domain Name Systems (DNS) allows these different alphabetical systems to be used as a fully qualified domain name (FQDN) by labeling them as internationalized domain name(s) (IDN). From Wikipedia: “An internationalized domain name (IDN) is an Internet domain name that contains at least one [character] displayed in software applications, in a [foreign-based.] language-specific script or alphabet, such as characters with diacritics or ligatures.”
Technical Problems
Phishing attacks can take advantage of this by using homographs to replace lookalike characters, such as writing facеbook instead of writing facebook, or gооglе instead of google.
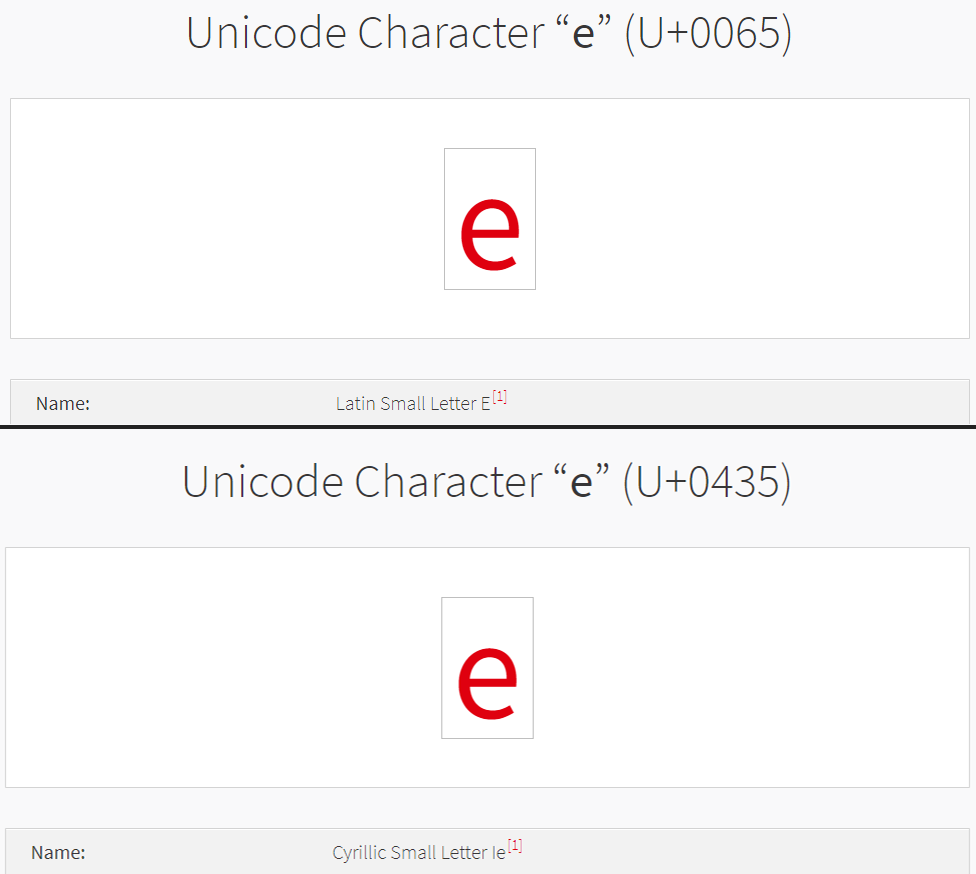
Additionally, DNS labels are not case-sensitive, meaning “ExAmPlE.com” and “example.com” are equivalent to each other. Because of this, phishers can take advantage of case-insensitivity and deceive people into falling for imposterous links.
Resources
[1] http://www.tcpipguide.com/free/t_DNSLabelsNamesandSyntaxRules.htm
[2] https://www.ietf.org/rfc/rfc3492.txt
[3]http://www.irongeek.com/i.php?page=security/out-of-character-use-of-punycode-and-homoglyph-attacks-to-obfuscate-urls-for-phishing
[4] https://en.wikipedia.org/wiki/Internationalized_domain_name
[5] https://en.wikipedia.org/wiki/Punycode
[6] https://en.wikipedia.org/wiki/Cyrillic_alphabets
[7] https://en.wikipedia.org/wiki/A_(Cyrillic)
[8] https://en.wikipedia.org/wiki/A
[9] https://en.wikipedia.org/wiki/IDN_homograph_attack
[10] https://www.compart.com/en/unicode/U+0435
[11] https://tools.ietf.org/html/rfc5892